用聚类算法实现mnist数据集分类
1、先导入mnist数据集
1
2
3
4
| import pandas as pd
import matplotlib.pyplot as plt
data = pd.read_csv("mnist_train.csv",header=None)
data.head()
|
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
... |
775 |
776 |
777 |
778 |
779 |
780 |
781 |
782 |
783 |
784 |
| 0 |
5 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 2 |
4 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 3 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 4 |
9 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
5 rows × 785 columns
1
| data.iloc[:,0].value_counts()
|
1 6742
7 6265
3 6131
2 5958
9 5949
0 5923
6 5918
8 5851
4 5842
5 5421
Name: 0, dtype: int64
2、切分数据集
1
2
| X=data.iloc[:,1:]
Y=data.iloc[:,0]
|
1
2
| from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=42)
|
3、SVM 随机森林 集成学习
1
2
3
4
5
6
7
8
9
10
11
12
13
| from sklearn.svm import SVC
from sklearn.pipeline import make_pipeline
from sklearn.ensemble import RandomForestClassifier, VotingClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import f1_score
rnd_clf = RandomForestClassifier(min_samples_leaf=2, n_estimators=200)
svm_clf = make_pipeline(StandardScaler(), SVC(probability=True,gamma='auto'))
vot_clf = VotingClassifier(estimators=[('rf',rnd_clf),('svc',svm_clf)],voting="soft")
from sklearn.metrics import accuracy_score
for clf in (rnd_clf,svm_clf,vot_clf):
clf.fit(X_train,y_train)
y_pred = clf.predict(X_test)
print(clf.__class__.__name__,f1_score(y_test, y_pred,average='weighted'),accuracy_score(y_test,y_pred))
|
RandomForestClassifier 0.9655389271780913 0.9655555555555555
Pipeline 0.961329629605016 0.9613131313131313
VotingClassifier 0.9700324936885113 0.970050505050505
4、用Kmeans聚类算法
1
2
3
4
5
6
7
8
|
from sklearn.cluster import KMeans
from sklearn import metrics
kmeans = KMeans(n_clusters=10)
kmeans.fit(X_train)
y_predict = kmeans.predict(X_test)
from sklearn.metrics import homogeneity_score, completeness_score, v_measure_score
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
clustering_metrics = [
metrics.homogeneity_score,
metrics.completeness_score,
metrics.v_measure_score,
metrics.adjusted_rand_score,
metrics.adjusted_mutual_info_score,
]
kmeans = KMeans(init="k-means++", n_clusters=10, random_state=0)
results=[]
for m in clustering_metrics:
print(m.__name__,m(y_test,y_predict))
results
|
homogeneity_score 0.4912474848781917
completeness_score 0.49862545459901814
v_measure_score 0.4949089740697011
adjusted_rand_score 0.3614689213307473
adjusted_mutual_info_score 0.49445572431055146
5、使用KNN算法学习
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
from sklearn.neighbors import KNeighborsClassifier
scoreList=[]
for i in range(3,10):
knn = KNeighborsClassifier(n_neighbors=i)
knn.fit(X_train,y_train)
scoreList.append(knn.score(X_test,y_test))
plt.figure(dpi=300)
plt.plot(range(3,10),scoreList)
plt.xlabel("k")
plt.ylabel("score")
plt.grid()
plt.show()
acc = max(scoreList)*100
print("Maxmum KNN score is {:.2f}%".format(acc))
|
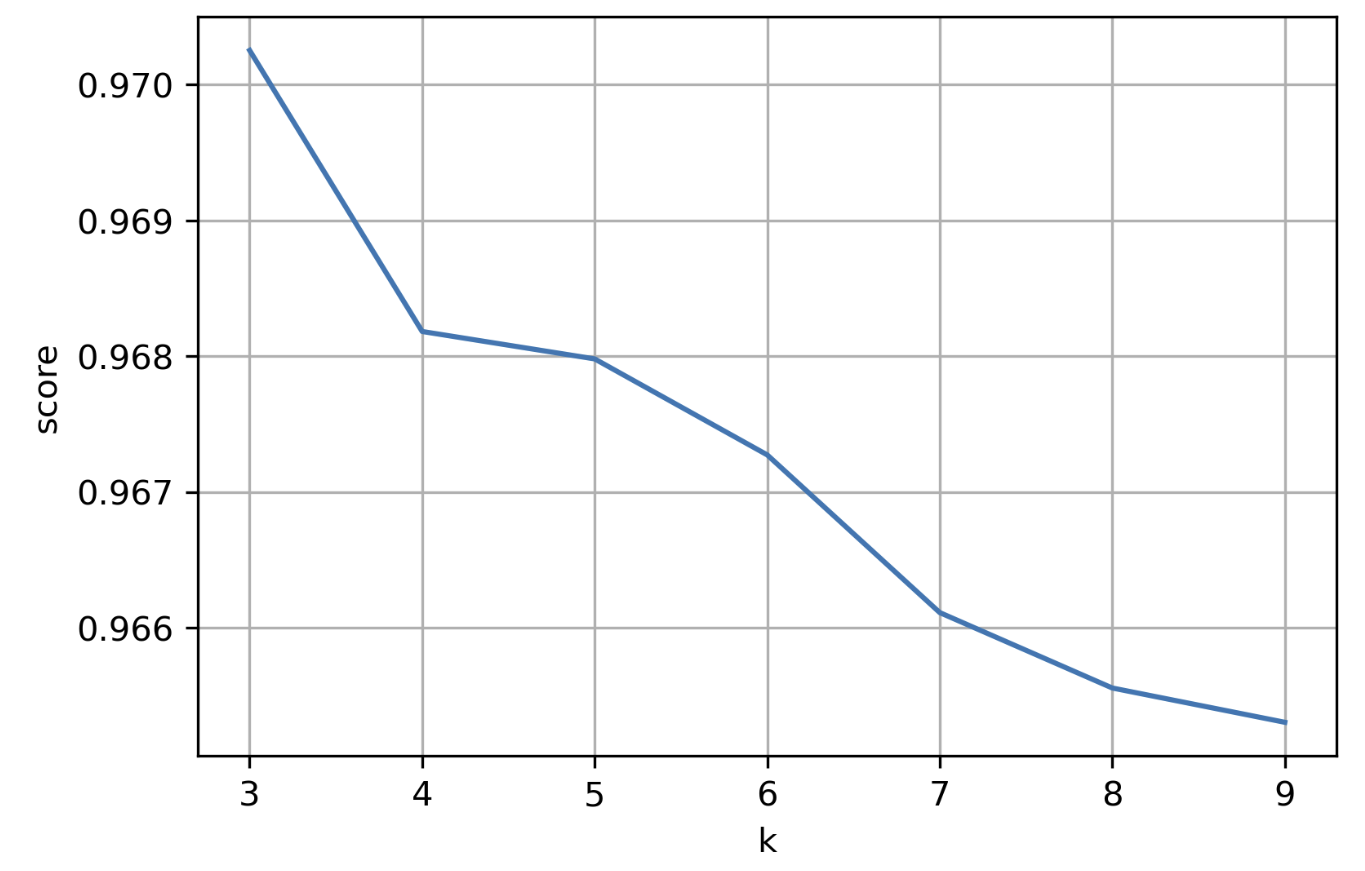
Maxmum KNN score is 97.03%
6、导入测试集datatest
1
2
3
| test = pd.read_csv("mnist_test.csv",header=None)
true_label=test.iloc[:,0]
true_label
|
0 7
1 2
2 1
3 0
4 4
..
9995 2
9996 3
9997 4
9998 5
9999 6
Name: 0, Length: 10000, dtype: int64
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
... |
775 |
776 |
777 |
778 |
779 |
780 |
781 |
782 |
783 |
784 |
| 0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 1 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 2 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 3 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 4 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| ... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
... |
| 9995 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 9996 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 9997 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 9998 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
| 9999 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
... |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
10000 rows × 784 columns
1
2
3
4
| best_knn = KNeighborsClassifier(n_neighbors=3)
best_knn.fit(X_train,y_train)
pre_y=best_knn.predict(XX)
pre_y
|
array([7, 2, 1, ..., 4, 5, 6], dtype=int64)
1
2
| from sklearn.metrics import accuracy_score
accuracy_score(true_label, pre_y)
|
0.9671